深圳理工大學(xué)(籌)計(jì)算機(jī)科學(xué)與控制工程學(xué)院李金艷研究團(tuán)隊(duì)在國際知名學(xué)術(shù)期刊Nature Communications上發(fā)表了題為“Optimizing differential expression analysis for proteomics data via high-performing rules and ensemble inference”的研究文章。該研究為蛋白質(zhì)組學(xué)數(shù)據(jù)的精準(zhǔn)分析提供了新的視角和方法���,對(duì)生物標(biāo)記物和藥物靶點(diǎn)的發(fā)現(xiàn)具有重要意義。
蛋白質(zhì)組學(xué)數(shù)據(jù)的差異表達(dá)分析是生物醫(yī)學(xué)領(lǐng)域中的關(guān)鍵技術(shù)��,它能夠幫助科學(xué)家準(zhǔn)確檢測(cè)特定表型的蛋白質(zhì)�。然而,由于分析流程中存在多種數(shù)據(jù)處理和分析工具的選擇����,確定最優(yōu)的分析流程一直是一個(gè)挑戰(zhàn)。為了解決這一問題�����,李金艷教授領(lǐng)導(dǎo)的研究團(tuán)隊(duì)對(duì)34,576種不同的差異分析流程進(jìn)行了超大規(guī)模的性能評(píng)估。
通過頻繁模式挖掘新技術(shù)�����,研究團(tuán)隊(duì)發(fā)現(xiàn)了一些能夠提高差異表達(dá)分析性能的規(guī)則����,并觀察到這些規(guī)則具有跨平臺(tái)的保守屬性。此外��,團(tuán)隊(duì)還構(gòu)建了分類模型����,證明了最優(yōu)分析流程的可預(yù)測(cè)性。在此基礎(chǔ)上�����,研究團(tuán)隊(duì)設(shè)計(jì)了一種集成推斷方法����,整合多個(gè)高性能差異分析流程的結(jié)果�,以擴(kuò)大差異蛋白質(zhì)組的覆蓋范圍并消除分析流程結(jié)果間的不一致性。
集成推斷方法不僅顯著提高了差異表達(dá)蛋白鑒定的準(zhǔn)確性��,還促進(jìn)了不同蛋白質(zhì)量化方法之間的信息有效整合。例如���,pAUC分?jǐn)?shù)和G-均值分別獲得了高達(dá)4.61%和11.14%的提高���。研究團(tuán)隊(duì)還發(fā)現(xiàn),使用不同蛋白質(zhì)量化技術(shù)的分析流程之間具有更好的性能互補(bǔ)性����,為設(shè)計(jì)更優(yōu)異的差異表達(dá)分析方法提供了指導(dǎo)。
為了便于蛋白組學(xué)數(shù)據(jù)分析領(lǐng)域的研究者使用�,研究團(tuán)隊(duì)構(gòu)建了網(wǎng)絡(luò)服務(wù)器OpDEA(http://www.ai4pro.tech:3838/)以及離線工具軟件包,以協(xié)助研究者進(jìn)行差異分析流程的選擇和差異表達(dá)分析�。
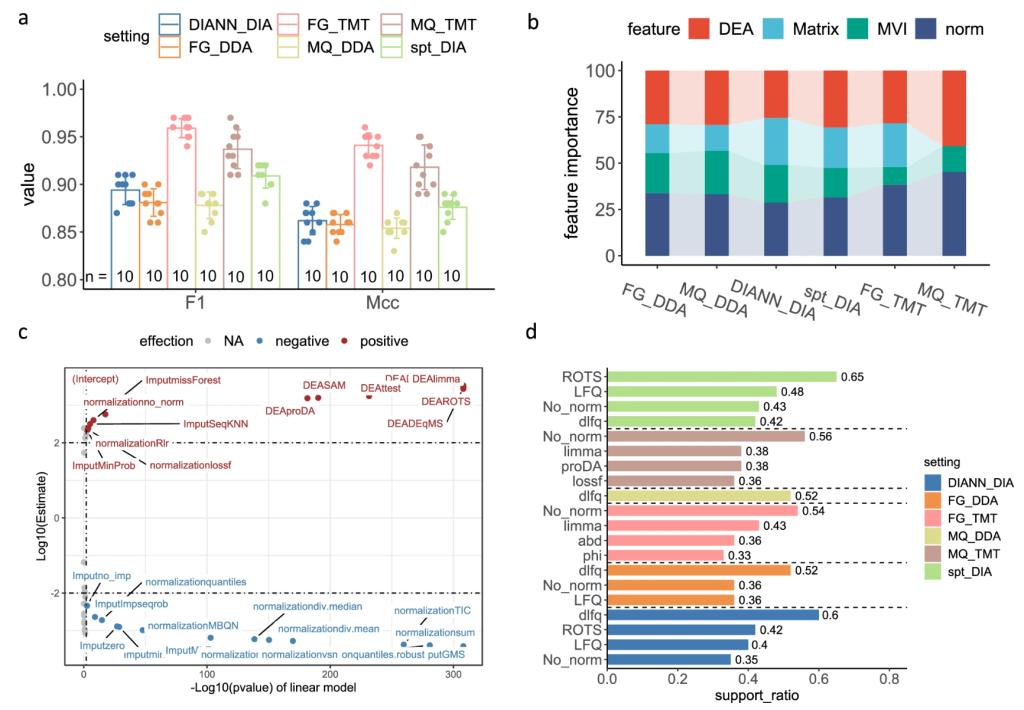
機(jī)器學(xué)習(xí)及數(shù)據(jù)挖掘技術(shù)分析差異表達(dá)分析流程的性能可預(yù)測(cè)性及保守性
閱讀原文



 粵公網(wǎng)安備44030002008114號(hào)
粵公網(wǎng)安備44030002008114號(hào)